TensorFlow是一個開源軟體庫,用於各種感知和語言理解任務的機器學習。目前被50個團隊用於研究和生產許多Google商業產品,如語音辨識、Gmail、Google 相簿和搜尋,其中許多產品曾使用過其前任軟體DistBelief。TensorFlow最初由Google大腦團隊開發,用於Google的研究和生產,於2015年11月9日在Apache 2.0開源許可證下發布。
簡而言之,TensorFlow是一個強大的機器學習框架。
TensorFlow是一個機器學習框架。如果您有許多資料,並且/或您正追求AI人工智慧的最先進技術,例如深度學習、神經網路⋯⋯等等,那TensorFlow也許會成為您新的超級好朋友!
那麼,我們就來介紹一下Tensorflow的基礎架構吧!
輔助閱讀: TensroFlow Go
TensorFlow模型的初探主要可以歸結為三個步驟。
載入與準備資料集,將範例從整數轉換為浮點數。

透過堆疊一張一張的層面(Layers)來建造Sequential model
選擇優化器(optimizer)和損耗函數(loss function)進行訓練

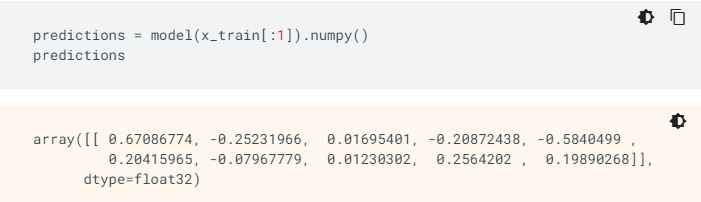
Model皆會回傳一組各自的logits或者log-odds評分給每個例子。
假設事件指的是二進制概率,那麼賠率(odds)指的就是成功的概率(p)與失敗的概略的比例(1-p)。舉例來說,假設給定的事件有90%的概率成功和10%的概率會失敗,在這個例子中賠率便是0.9/0.1=0.9。
Log-odds就是賠率的對數,按照慣例,對數是指自然對數,但對數其實可以是任何大於1的數字,照著自然對數來,則我們的例子的對數便是log-odds = ln(9) = 2.2。
Softmax: 一種在多類別區分模組中為每個可能的類別產生機率的方法。概率家總會等於1.0,舉例來說softmax可能會決定某張圖片可能是狗的機率為0.9,是貓的機率為0.08和是馬的機率為0.02。(也稱作full softmax)
Multi-class classification: 分類問題區分多於兩個類別以上。舉例來說,世界上大概有128種不同種類的楓樹,所以模組將楓樹進行分類辨識多類別分類。反過來說模組只將電子信件區分為兩個類別(垃圾郵件或者不是)則是二進制分類模組(binary classification)。
Binary classification: 一種將輸出的結果分類為互斥集分類任務,舉例來說一種機器學習模組評估信件訊息並產生輸出為”垃圾郵件”或者”不是垃圾郵寄”便是二進制區分器(binary classifier)
讓我們下篇再繼續!
參考資料:
https://zh.wikipedia.org/wiki/TensorFlow
https://kozyrk.medium.com/chinese-all-about-tensorflow-f1e2ab1b89b1

